Introduction
Just a few preliminary points before we start:
- This is not a git tutorial. ( If you want one check https://try.github.io/ )
- This is my opinion only, but hopefully you might learn something or find something of use.
- This guide is with puppet architecture in mind, although most things should still be relevant if you apply the same thought process.
- I won’t be going into CI/CD pipelines, but you sure can’t have a decent one without good version control structure.
- Sorry SVN guys, this guide will be based on Git.
- This is focused on the workflow and structure as opposed to the implementation.
- Want a TL;DR, you can check the conclusion at the end
Why are you writing this?
Now those points are cleared up, I will discuss why I decided to write an article on version control. The short answer is because time after time I see bad implementations, this can occur for numerous reasons. A large portion of the time, the scope for using version control starts off small and easily manageable, then grows over time and the priorities lie elsewhere thus the version control architecture never gets refactored and it gets out of hand. Another reason can be that people don’t know where to start with integrating version control into pre-existing infrastructure, sometimes people just put things into git ad-hoc and end up with an unorganised mess. Of course there are also times where people don’t understand or know how to correctly architect the structure of the repository. Whatever the reason may be, I am hoping that it might provide some clarity into what seems to be a misunderstood topic.
Why is puppet an additional premise to the article?
I feel configuration management is a particularly bad pitfall when it comes to version control and the DevOps community and getting it right can be tricky. I chose puppet specifically just due to personal preference/experience but there is no reason why the same concepts can’t be applied to other CM tools, or even other projects that require a version control implementation.
So without furthermore, let’s get into the main topic of discussion.
Basic concepts of version control
To help break this down I will try and break down some key terms and talk about them individually:
Repository –
A repository is like a container of code – it can contain multiple versioned files in a data structure. A repository can be thought of like a linux directory or a windows folder, there are directories and sub-directories which maintain the organisation and structure of the repository, these contain the files that are versioned. A repository should have a purpose defined upon creation and should only contain code that is relevant to that purpose. The purpose should not be generic, but specific to what the code in the repository is going to do.
Artifact –
An artifact can mean different things, when I refer to something as an artifact I am talking about a file. A file that is part of the overall codebase and is relevant to the purpose of the repository is considered an artifact. These artifacts have a version number and a commit message relevant to the last change made to the file.
Codebase –
Another word that has multiple meanings, but in this context I am referring to all the code within the repository as one codebase. The reason this is important is because it highlights that all the code in the repository is one version-able item as well as the individual versions of the files that it contains. If you make changes to a file, you change the version of the codebase. This means if you have your code deployed in production and you update a file in the repository, you are no longer working from the same codebase.
Organisations/Groups –
Organisations/Groups of repositories is a nice way to structure and organise related repositories. Github has organisations for this whereas GitLab has groups. You can also use git submodules to a similar effect if you would like a pure git way of doing things. For instance, say you have a large amount of in-house modules that you have developed and each module was its own repository, then you could group these together by creating a top-level organisation/group called MyCompanyName-Modules.
Branches –
Braches are a part of the git workflow, they are a way of developing with your code still in version control without affecting the stable version of the code that is in the master branch. This also allows multiple developers to be working on different features at the same time and eventually merge with the master branch. This diagram explains it much better, after all a picture speaks a thousand words.
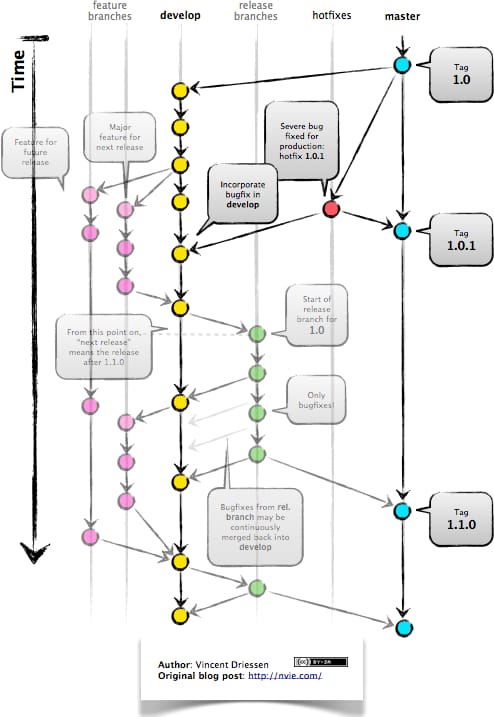
If you want more information on Git flow I highly recommend checking out the creator of this diagram’s blog which has a brilliant article on the subject. The article can be found here:
https://nvie.com/posts/a-successful-git-branching-model/?
Now we have some of the nomenclature out of the way, I feel the best place to start talking about how things should be, is to embrace the pessimist and talk about the common mistakes people make when architecting their version control system.
Monolithic repositories
Number one offender on the list and by far the most common. A monolithic repository contains lots of different code for different purposes and has no overall purpose. The reason this is so common is due to scaling, meaning that the use of version control is minimal and builds up over time with everyone just chucking everything into the same repository and it never gets refactored due to other priorities. This is where a clearly defined purpose for your repository is integral to the structure and keeps all the code relevant to a single goal. If you have 6 puppet modules that you want to store in version control, you may be thinking “OK, I will create a repository called PuppetModules and store my modules in here”. If you have this kind of structure then I am sorry to say, while being slightly more organised, this is still a monolithic repository. The code in one module is separate and does not impact the code in the other (not talking about dependancies), each module is it’s own codebase and has it’s own purpose thus meaning it needs its own repository. As previously stated, if you change any file in the repository you are changing the version of the overall codebase that you are working from, this means if you make updates to one module then you are changing the version of another if it is in the same repository. Your repository should contain code for one “thing” whatever that “thing” might be.
Push to master branch
This is more of a usage issue than a structure issue but it is too common to be left out of the list. In my opinion, there is never a good reason to push changes directly to the master branch (apart from maybe the initial commit) , all changes should be made by using the following workflow:
- Pulling down the latest version of the repository
- Creating a feature branch
- Make the changes that are required
- Write a commit message describing the changes you have made
- Push the changes you made you made to your feature branch
- Test the changes you made on the feature branch
- If all the changes relevant to the new feature have been made and completed, raise a merge request to the master branch
- Get a colleague to perform a code review and check the changes you have made
- If your changes have been checked and tested then your feature branch can be merged
The code in the master branch should be the stable, working and tested version of the code that always builds without error. Pushing code directly to master means that you are changing the state of the codebase with code that has not been tested through the appropriate channels. Also, the feature branch process helps track what changes have updated the codebase version rather than tracking changes to individual versions of files.
Making changes to files where the repository is synced to
People may differ in opinion on this one, but I feel like I have a strong case on why this should never be done. To clarify, this means that the code that is in your repository should be edited locally and not in the location where your code is being used. For example, say you have a simple website of which all the code is in a git repository with the live version being stored on a web server at the web-root directory, some people may edit the files in the web-root directory and then push to the repository to update the changes that were made. The reason this is the wrong thing to do is because the version that is being used currently should always be an exact match of the code that is in version control. As soon as you edit the files that are in use, you have put the server out of sync with the version control system. Take this scenario for example: one developer is making changes to the website directly and suddenly he is called away to work on a P1, he forgets to commit the changes he made and the server is left out of sync with git. Another developer makes his changes through the correct process and pulls down to the server completely overwriting the previous developers work. Not only this, but the server could crash and need to be rebuilt and if you don’t have the code checked in to git you will have lost the changes you made. In that scenario it is obviously wrong to make changes to a live website directly, but when it comes to more subtle things like changing the directory structure or just adding a file to a working repository, people tend to think it is more appropriate to do so yet you still run the exact same risks of losing the work you have done and putting the server in an unknown state.
Now that we’ve covered the common mistakes that are made, I am going to start talking about how things should be structured. I will be using some puppet specifics and will be providing a skeleton architecture for how I think puppet should be versioned.
How to structure you git repository for puppet
Let’s take this as an example of puppet infrastructure. As this is about version control and not puppet, I’m not going to explain how to segregate and setup your puppet environments but a good setup will help tie into a good structure for your version control system.
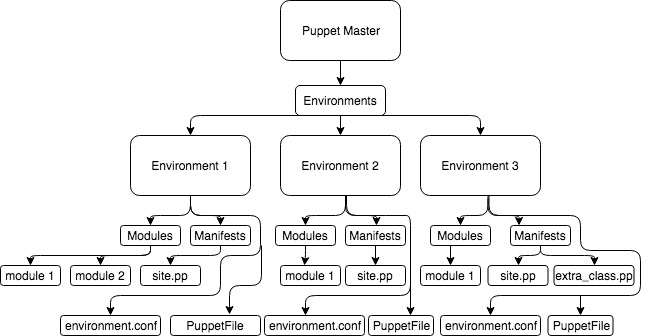
So here are three different architectural structures you could have for this environment, in order of worst to best:
Worst –
- One repository with a base directory at Environments
- All Environments backed up together
- No separate versioning for manifests
- Duplicate modules backed up unnecessarily
Slightly better –
- Repository per environment
- Environment is it’s own codebase
- Duplicate modules backed up unnecessarily
- Puppet forge modules backed up unnecessarily
- Unrelated modules backed up together
Better –
- Repository per environment with the modules directory backed up separately
- Only environment specific code backed up in the environment repository
- Unrelated modules still backed up together
- Puppet forge modules back up unnecessarily
- Duplicate modules backed up unnecessarily
The best way I know how –
That’s right, another flow diagram:
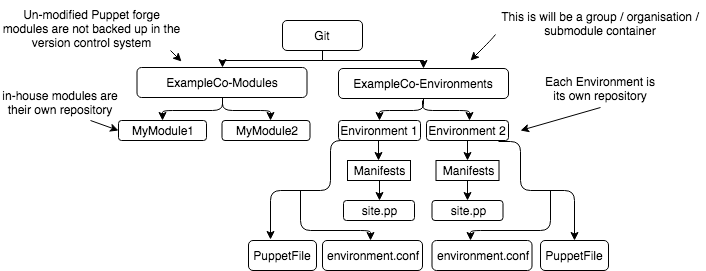
With git structured in this way, you are using the Puppetfile to manage the modules that you have in your environment. This means that you manage all the modules you want to have installed in your environment with a single version-able file and without keeping redundant copies of the modules for every environment. The puppet file looks like the following:
#!/usr/bin/env ruby
#^syntax detection
~
forge “https://forgeapi.puppetlabs.com”
~
# use dependencies defined in metadata.json
#metadata
~
mod ‘exampleCo-module1’,
:git => “https://oauth2:<mygitlabapitoken@gitlab.exampleCo.com/ExampleCo-Modules/MyModule1.git”
~
mod ‘exampleCo-module2’,
:git => “https://oauth2:<mygitlabapitoken@gitlab.exampleCo.com/ExampleCo-Modules/MyModule2.git”
~
mod ‘puppetlabs-concat’, ‘4.0.0’
mod ‘puppetlabs-firewall’, ‘1.12.0’
mod ‘puppetlabs-ntp’, ‘7.1.1’
Here, we are using the default Version Control system being puppet forge, which is where it will pull modules from that have not been developed or modified by your company and you can specify a version of the module that suits your environment. You can also point to your own modules by specifying the git option and pointing it to the location of your module in your repository. The Puppetfile is also a version controlled artifact, as well as controlling the versions of the modules you use, meaning this is stored in the same repository as your environment and is treated as a “Build file” to setup your environment and maintain the modules within it.
Restoring your puppet master from version control
You can obviously automate this process or have a different restore mechanism, but this is just to show you how the version control system works to ensure your code is in a valid, stable and known state, as well as making light work of restoring your entire environment. Let’s say that a clumsy developer deletes your entire environment that you need to backup, you don’t need to cherry pick the bits you need out of your repository, all you need to do is follow the steps below:
- cd /<puppetdir>/code/environments/
- git clone http://oauth2:<mygitapitoken>@<mygiturl>/<comapany_name>-Environments/<environment_name>
- cd <environment_name>
- /path/to/librarian-puppet install
Provided that you have been following the recommendations and have the environment setup as above, git will pull down:
- manifests directory + any manifests
- environment.conf
- Puppetfile
Once you run librarian-puppet install, you should have a new directory with all the modules you had previously installed at all the correct versions with their dependancies installed if they were specified in the metadata.json of the module (if not you will need to manually specify these in the Puppetfile).
Conclusion
Hopefully this was comprehensive enough to give you a good understanding of how to version control your puppet infrastructure and not fall into the common pitfalls that occur. I will finish up by recapping over some points that were made:
- Define a purpose for every repository you create. It can be for a module, environment, webapp, website or anything, but it shouldn’t be more than one.
- Remember that your repository as a whole is your codebase, this has a version just as the files contained within it have. Change a version of a file, you change the version of the codebase.
- Test. Test once more and test again. Remember that everything that gets committed into the master branch should be reliable, stable and tested code. Test your code on a feature branch and then only implement once it has been code reviewed and tested.
- Decline any merge request that doesn’t have a decent commit message detailing the changes that were made. Git helps by highlighting lines that were changed but nobody wants to read through the whole code just to workout what you have changed and why.
- Actually check the merge requests before you accept them, may be a pain but it will help you in the long run I promise you.
- Never change the code in the location it is being used. Ever.
- Be kind to your colleagues. You can commit the code and even push it to your feature branch but don’t raise 50 merge requests for little corrections and line adds. Make the changes you need and bundle your commits for a final push where they can be reviewed together.
So, hopefully this provides some insight into version control and you learnt something new. If not, then I am sure it would of given you at least a few horror flashbacks of times where you have come across something similar and can be happy that you have a decent setup.
Until next time… 🙂